
Tag: multi-GPU inference
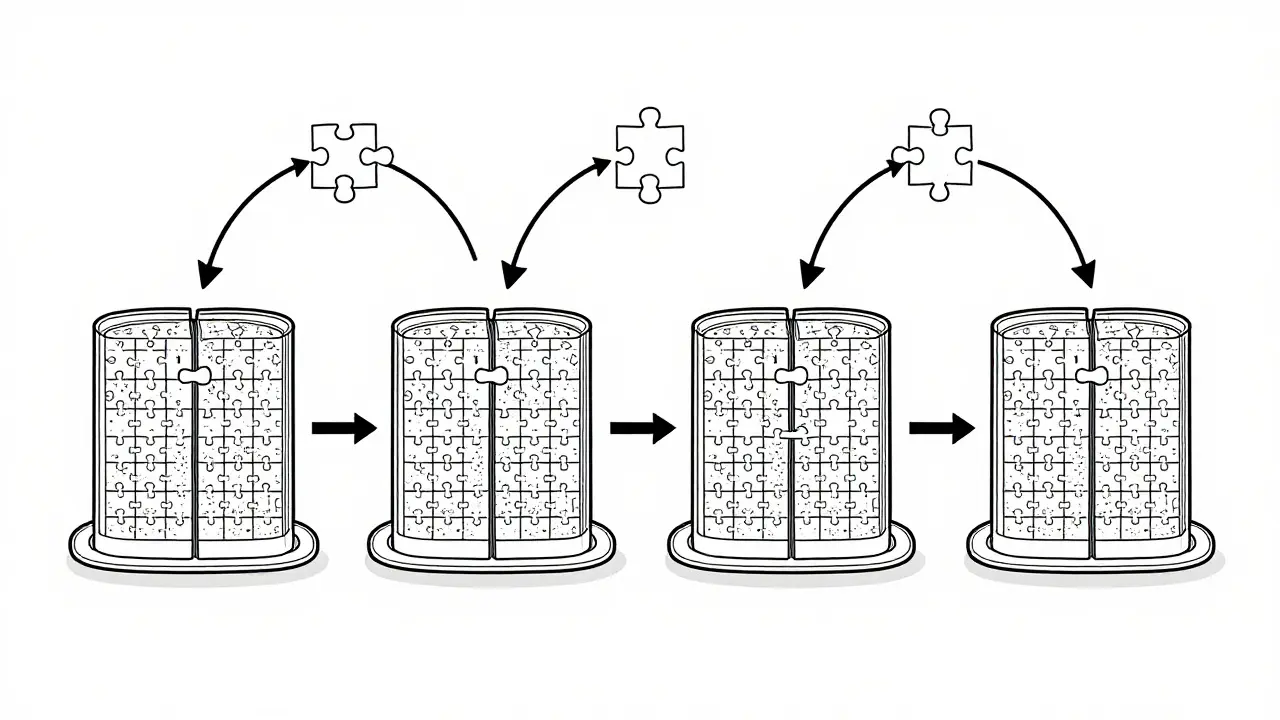
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Tokenizer Design Choices and Their Impacts on LLM Quality
Apr, 6 2026

Prompt Injection Defense: How to Sanitize Inputs for Secure Generative AI
May, 11 2026
Community Resources for New Vibe Coders: Courses, Templates, and Forums
Jul, 6 2026
Private Prompt Templates: How to Prevent Inference-Time Data Leakage in AI Systems
Aug, 10 2025

Contact Center ROI from Generative AI: Handle Time, CSAT, and First Contact Resolution
Jun, 14 2026