
PCables AI Interconnects
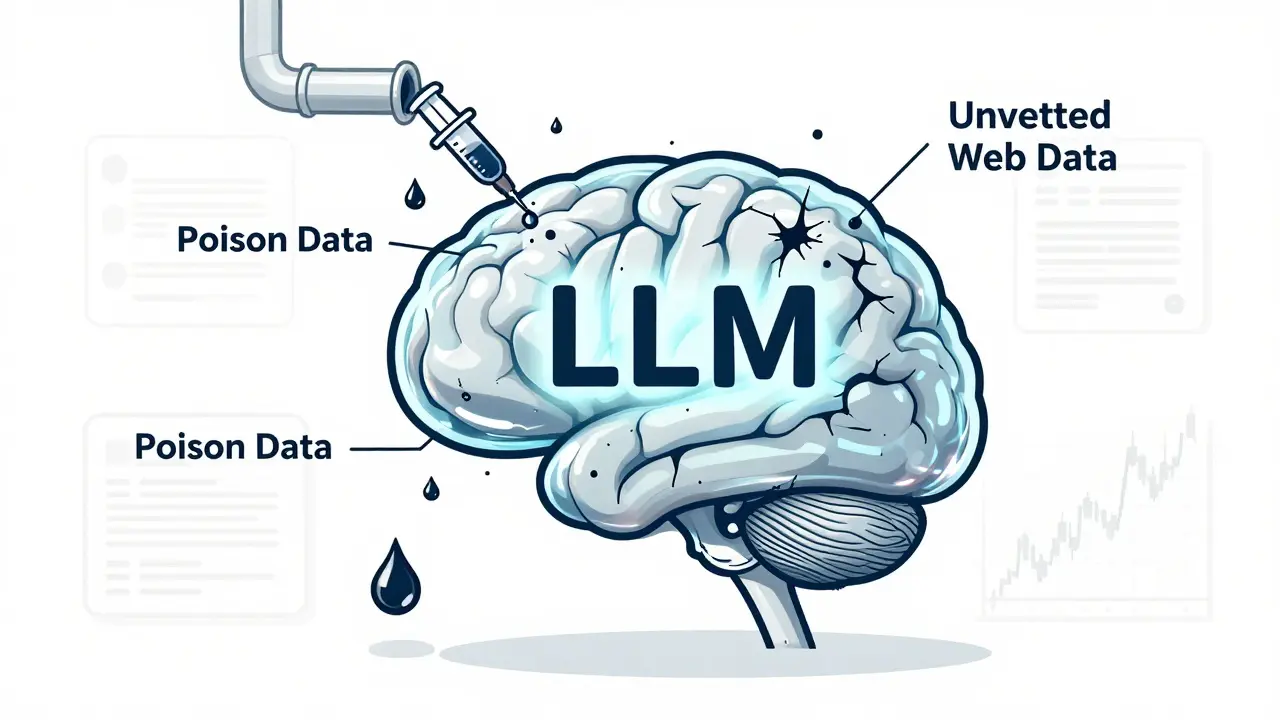
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.

Error-forward debugging lets you feed stack traces directly to LLMs to get instant, accurate fixes for code errors. Learn how it works, why it's faster than traditional methods, and how to use it safely today.
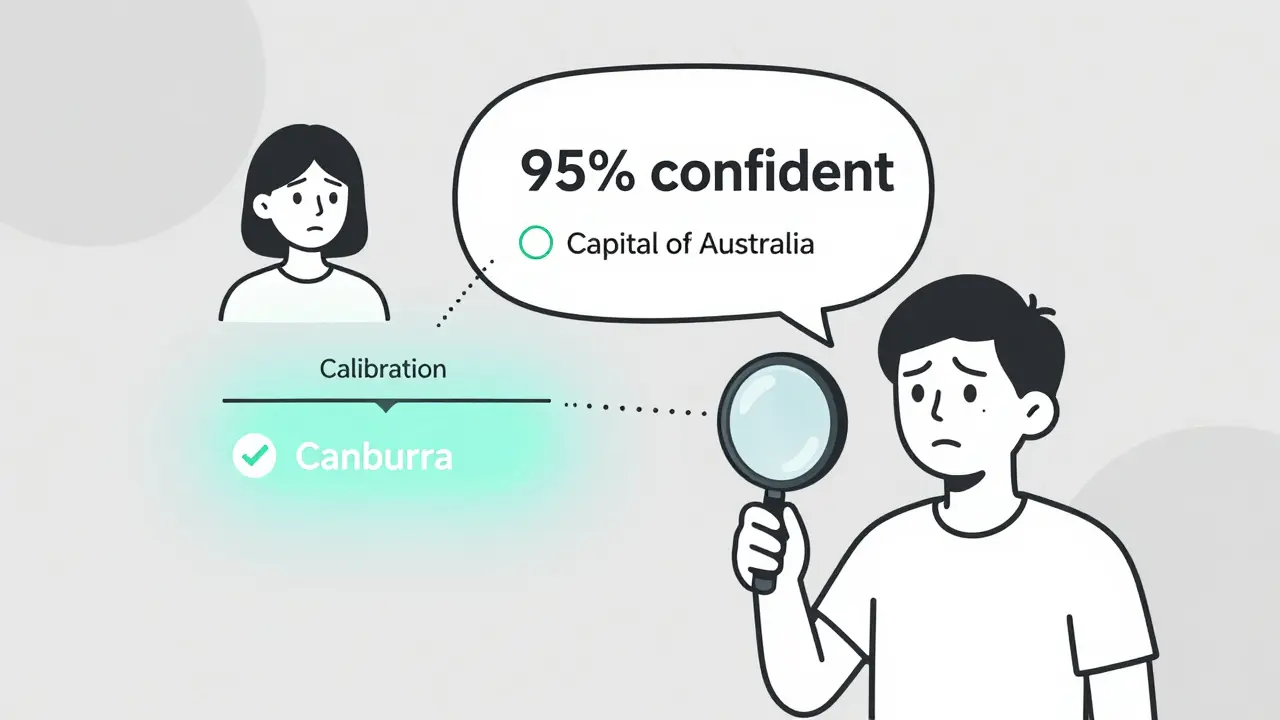
Most LLMs are overconfident in their answers. Token probability calibration fixes this by aligning confidence scores with real accuracy. Learn how it works, which models are best, and how to apply it.
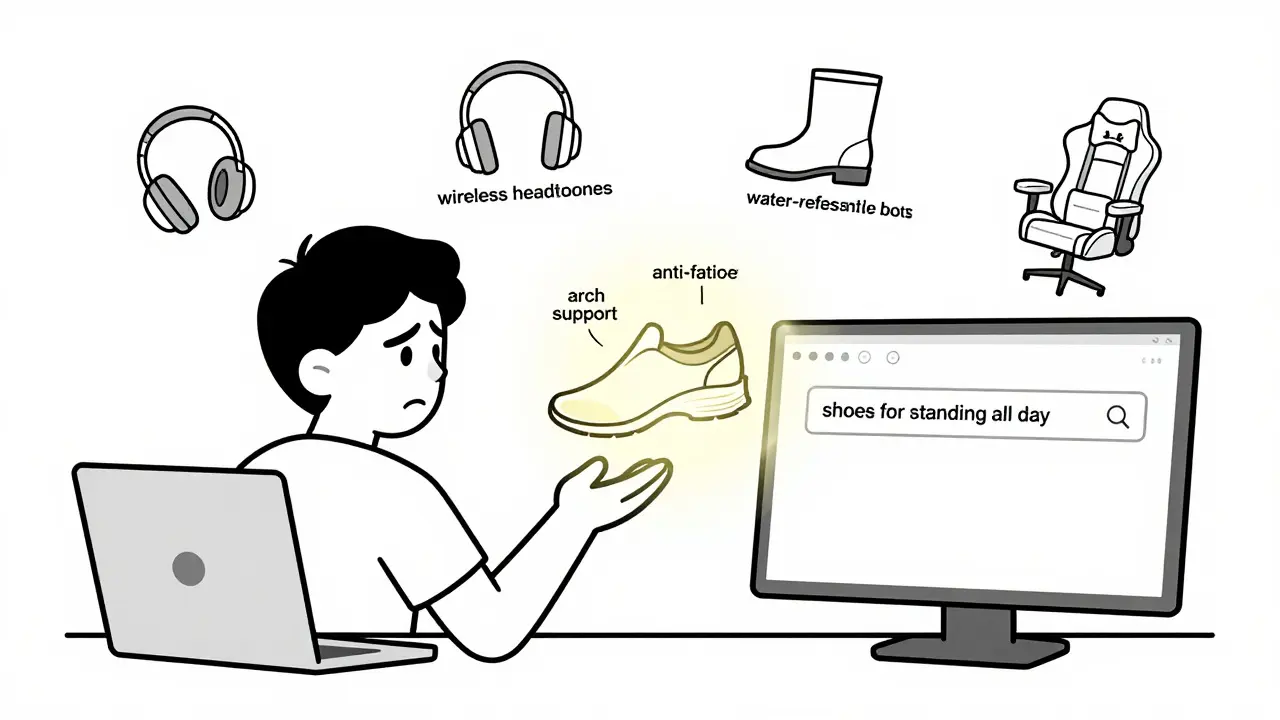
LLM-powered semantic search is transforming e-commerce by understanding user intent instead of just matching keywords. See how it boosts conversions, reduces abandonment, and what you need to implement it successfully.

Pattern libraries for AI are reusable templates that guide AI coding assistants to generate secure, consistent code. Learn how they reduce vulnerabilities by up to 63% and transform vibe coding from guesswork into reliable collaboration.
Vibe coding teaches software architecture by having students inspect AI-generated code before writing their own. This method helps learners understand design patterns faster and builds deeper system-level thinking than traditional syntax-first approaches.
Performance budgets set clear limits on page weight, load time, and resource usage to keep websites fast. Learn how to define, measure, and enforce them using real tools and data to improve user experience and SEO.
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.

Learn how vibe-coded internal wikis and demo videos capture team culture to improve onboarding, retention, and decision-making. Discover tools, pitfalls, and real-world examples that make knowledge sharing stick.
Learn how to visualize LLM evaluation results effectively using bar charts, scatter plots, heatmaps, and parallel coordinates. Avoid common pitfalls and choose the right tool for your needs.

Speculative decoding and Mixture-of-Experts (MoE) are cutting LLM serving costs by up to 70%. Learn how these techniques boost speed, reduce hardware needs, and make powerful AI models affordable at scale.

Generative AI coding assistants like GitHub Copilot and CodeWhisperer are transforming software development in 2025, boosting productivity by up to 25%-but only when used correctly. Learn the real gains, hidden costs, and how to avoid common pitfalls.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Chunking Strategies That Improve Retrieval Quality for Large Language Model RAG
Dec, 14 2025

Transformer Efficiency Tricks: KV Caching and Continuous Batching in LLM Serving
Sep, 5 2025
Token Probability Calibration in Large Language Models: How to Fix Overconfidence in AI Responses
Jan, 16 2026

Error-Forward Debugging: How to Feed Stack Traces to LLMs for Faster Code Fixes
Jan, 17 2026

Performance Budgets for Frontend Development: Set, Measure, Enforce
Jan, 4 2026