
Author: Phillip Ramos - Page 4

Non-developers are building apps faster than ever using AI tools-but most don’t know how to secure them. Learn the three rules to avoid breaches, reduce risk, and ship safe vibe-coded apps without writing a line of code.
Prompt robustness ensures AI models handle typos, rephrasings, and messy inputs without crashing. Learn how MOF, RoP, and keyword choices make LLMs more reliable in real-world use.

This article explains how AI-generated dark patterns manipulate users, with real examples and regulations. Learn a 5-step ethical audit to prevent deceptive designs and protect digital trust.

Discover why traditional metrics fail for compressed LLMs and how modern protocols like LLM-KICK and EleutherAI LM Harness accurately assess performance. Learn key dimensions, implementation steps, and future trends in model compression evaluation.

Discover how rotary embeddings, ALiBi, and memory mechanisms enable AI models to handle up to 1 million tokens. Learn key differences, real-world impacts, and future trends in long-context AI.

Reinforcement Learning from Prompts (RLfP) automates prompt optimization using feedback loops, boosting LLM accuracy by up to 10% on key benchmarks. Learn how PRewrite and PRL work, their real-world gains, hidden costs, and who should use them.

Generative AI can now describe images for alt text, helping make the web more accessible. But accuracy gaps, especially for people with disabilities, mean human review is still essential.
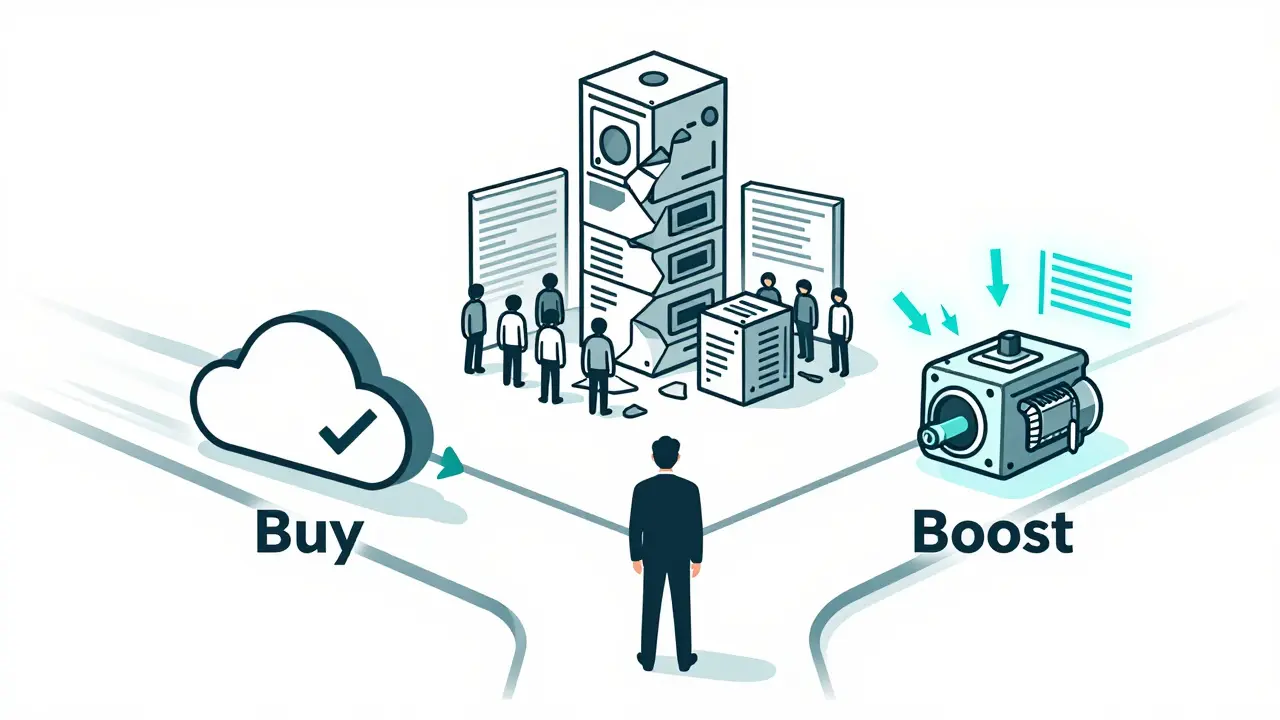
A practical guide for CIOs on choosing between building or buying generative AI platforms. Learn when to buy, boost, or build based on cost, risk, speed, and business impact - backed by 2024-2025 enterprise data.

Learn how to manage defects, technical debt, and enhancements in vibe coding using AI-assisted development. Without proper backlog hygiene, AI creates more work than it solves.

AI-generated interfaces are breaking web accessibility standards at scale. WCAG wasn’t built for dynamic AI content, and real users are paying the price. Here’s why compliance is failing-and what actually works.
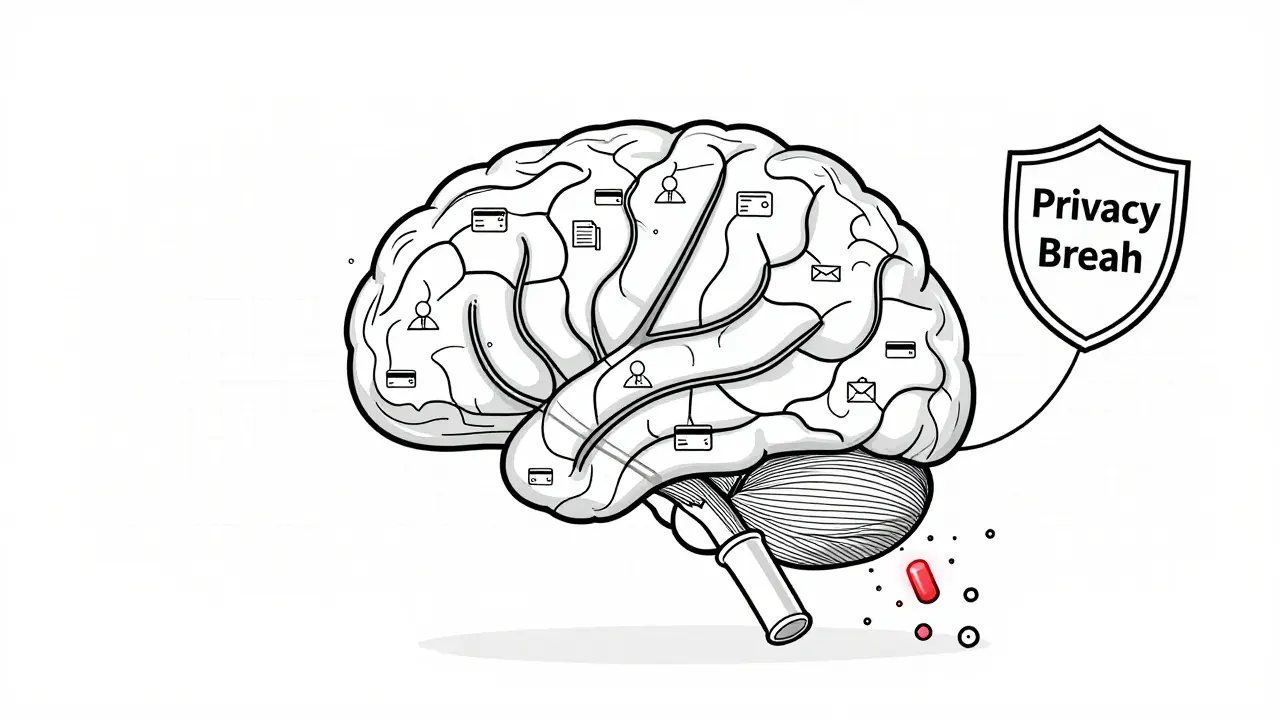
LLMs memorize personal data, making traditional privacy methods useless. Learn the seven core principles and practical controls-like differential privacy and PII detection-that actually protect user data in 2026.

Vibe coding boosts weekly developer output by up to 126% by automating boilerplate, UI, and API tasks. Learn how AI-assisted tools like GitHub Copilot drive real productivity gains-and how to avoid the hidden traps of technical debt and security risks.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Prompt Sensitivity in Large Language Models: Why Small Word Changes Change Everything
Oct, 12 2025
Customer Journey Personalization Using Generative AI: Real-Time Segmentation and Content
Mar, 17 2026

Long-Context AI Explained: Rotary Embeddings, ALiBi & Memory Mechanisms
Feb, 4 2026
Multi-GPU Inference Strategies for Large Language Models: Tensor Parallelism 101
Mar, 4 2026
Accessibility Regulations for Generative AI Products: WCAG and Assistive Features
Mar, 6 2026