
Author: Phillip Ramos - Page 4
Discover how dropping token costs in Generative AI are transforming business economics. Learn practical strategies to optimize spending, unlock scalable use cases, and leverage new infrastructure trends in 2026.
Explore how generative AI transforms curriculum design, assessment, and tutoring in 2026. Discover top tools, ethical challenges, and strategies for effective integration in modern education.

A practical guide to selecting the best vibe coding platform for your team in 2026. Compare Replit, Windsurf, Noca, and Builder.io on cost, security, and ease of use.
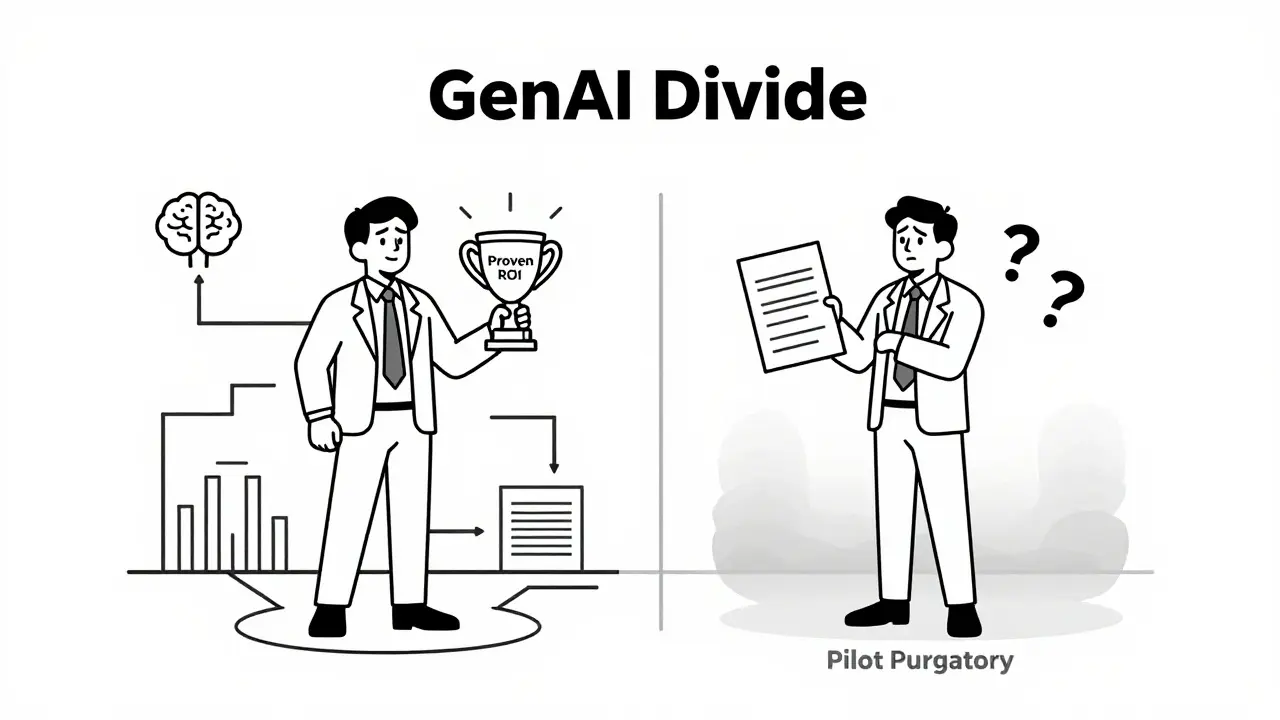
Discover why 95% of companies fail to prove Generative AI ROI and how to fix it. Learn advanced attribution methods like counterfactual analysis to isolate AI effects from market noise.
Explore how next-gen LLMs master instruction following through SFT, DPO, AutoIF, and activation steering. Learn why models like GPT-4 and Llama-3 excel at complex tasks and what's next for AI alignment.

Learn how Human-in-the-Loop (HitL) review systems catch AI hallucinations before they reach users. Explore best practices, costs, and regulatory requirements for effective enterprise AI oversight.

Learn how to secure AI-generated code with branch protection rules covering SAST, SCA, secrets scanning, and supply chain defenses against hallucinations and typosquatting.

Discover how interactive clarification prompts in generative AI reduce hallucination risk by asking users targeted questions before answering. Learn why this shift from guessing to collaborating improves accuracy and user satisfaction.
Discover how Large Language Models master language through self-supervised learning and attention mechanisms. Explore the technical foundations of syntax and semantic capture.

Learn how to defend against prompt injection in Generative AI apps. This guide covers input sanitization, LLM guardrails, and defense-in-depth strategies to secure your AI applications.

Discover how LLMs transform marketing analytics with faster trend detection and deeper campaign insights. Learn about GEO, implementation costs, and avoiding AI pitfalls in 2026.

Learn how to accurately measure Generative AI ROI using a three-tiered framework covering productivity, quality, and transformation. Discover why traditional metrics fail and how to track both hard and soft returns.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

How Large Language Models Are Creating Personalized Learning Paths in Education
Feb, 14 2026

Why Understanding Every Line of AI-Generated Code Isn't the Goal in Vibe Coding
Mar, 27 2026

Vibe Coding Adoption Metrics and Industry Statistics That Matter
Mar, 29 2026
Few-Shot Fine-Tuning of Large Language Models: When Data Is Scarce
Feb, 9 2026

How to Optimize Your Contact Center with Generative AI: Summaries, Sentiment, and Routing
Apr, 19 2026