
Author: Phillip Ramos - Page 12
LLMs memorize personal data, making traditional privacy methods useless. Learn the seven core principles and practical controls-like differential privacy and PII detection-that actually protect user data in 2026.

Vibe coding boosts weekly developer output by up to 126% by automating boilerplate, UI, and API tasks. Learn how AI-assisted tools like GitHub Copilot drive real productivity gains-and how to avoid the hidden traps of technical debt and security risks.

Modern generative AI isn't powered by bigger models anymore-it's built on smarter architectures. Discover how MoE, verifiable reasoning, and hybrid systems are making AI faster, cheaper, and more reliable in 2025.
Containerizing large language models requires precise CUDA version matching, optimized Docker images, and secure model formats like .safetensors. Learn how to reduce startup time, shrink image size, and avoid the most common deployment failures.
Learn how to choose optimal batch sizes for LLM serving to cut cost per token by up to 87%. Discover real-world results, batching types, hardware trade-offs, and proven techniques to reduce AI infrastructure costs.

Vibe coding lets fintech teams build tools with natural language prompts instead of code. Learn how mock data, compliance guardrails, and AI-powered workflows are changing how financial apps are developed-without sacrificing security or regulation.
Learn how hardware-friendly LLM compression lets you run powerful AI models on consumer GPUs and CPUs. Discover quantization, sparsity, and real-world performance gains without needing a data center.
Procurement checklists for vibe coding tools must include security controls and legal terms to avoid data breaches, copyright lawsuits, and compliance fines. Learn what to demand from AI coding tools like GitHub Copilot and Cursor.
NLP pipelines and end-to-end LLMs aren't competitors-they're complementary. Learn when to use each for speed, cost, accuracy, and compliance in real-world AI systems.
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.

Error-forward debugging lets you feed stack traces directly to LLMs to get instant, accurate fixes for code errors. Learn how it works, why it's faster than traditional methods, and how to use it safely today.
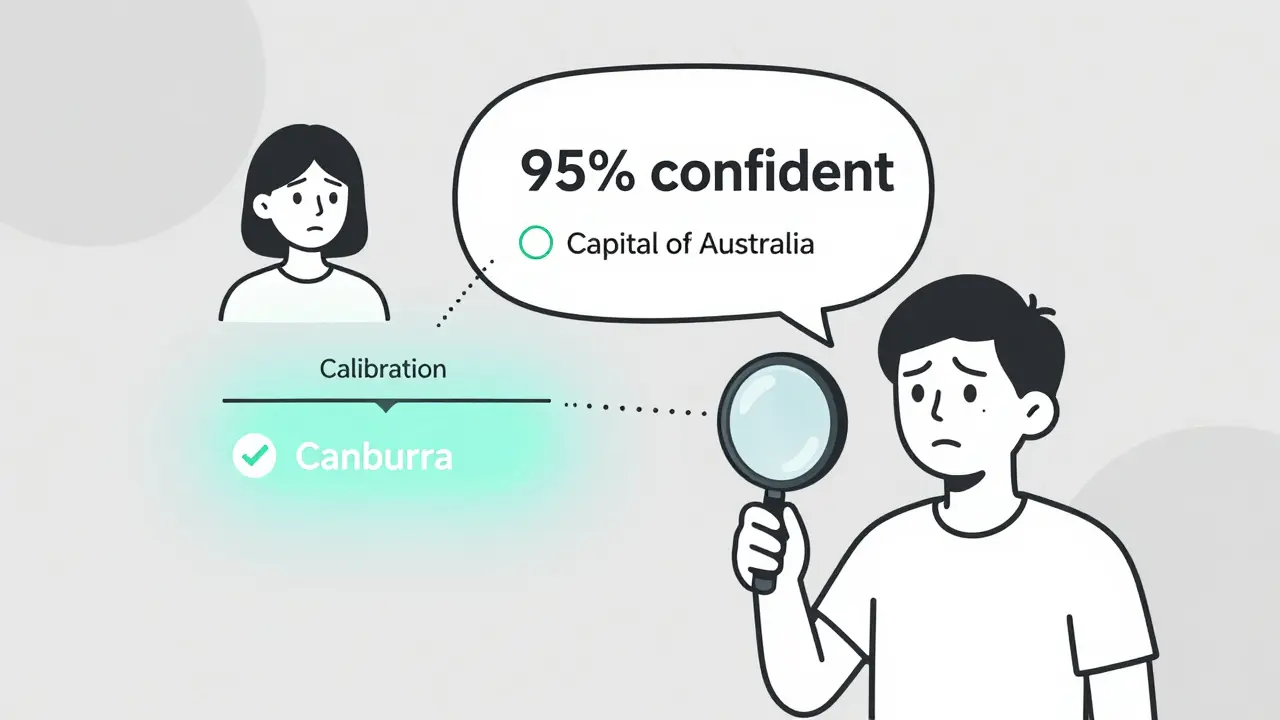
Most LLMs are overconfident in their answers. Token probability calibration fixes this by aligning confidence scores with real accuracy. Learn how it works, which models are best, and how to apply it.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Dependency Injection in Vibe-Coded Backends: Testability and Modularity
May, 26 2026

Service Level Objectives for Maintainability: Key Indicators and How to Set Alerts
Mar, 16 2026
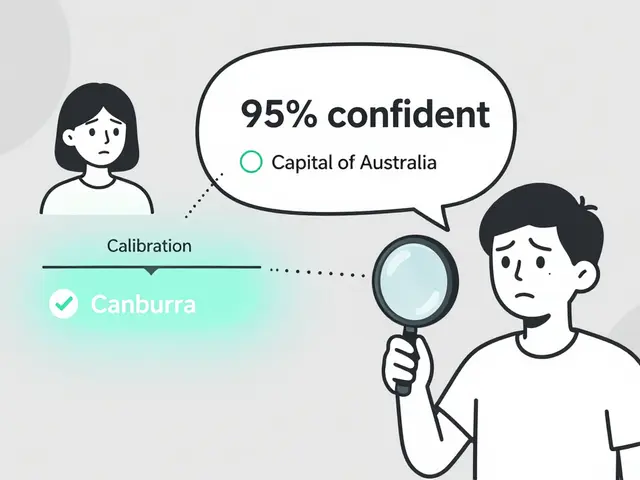
Token Probability Calibration in Large Language Models: How to Fix Overconfidence in AI Responses
Jan, 16 2026
Private Prompt Templates: How to Prevent Inference-Time Data Leakage in AI Systems
Aug, 10 2025

Compressed LLM Evaluation: Essential Protocols for 2026
Feb, 5 2026