
Author: Phillip Ramos - Page 10

Sandboxing external actions in LLM agents prevents dangerous tool access by isolating processes. Firecracker, gVisor, and Nix offer different trade-offs between security and performance. Learn which method fits your use case.

Structured prompts using role, rules, and context are the key to reliable enterprise LLM use. Learn how role-based prompting, chain-of-thought reasoning, and iterative testing improve accuracy, reduce hallucinations, and align outputs with business needs.

Choosing the right embedding model for your enterprise RAG pipeline isn't about benchmarks - it's about speed, security, and domain-specific accuracy. Learn what actually works in production and how to avoid costly mistakes.
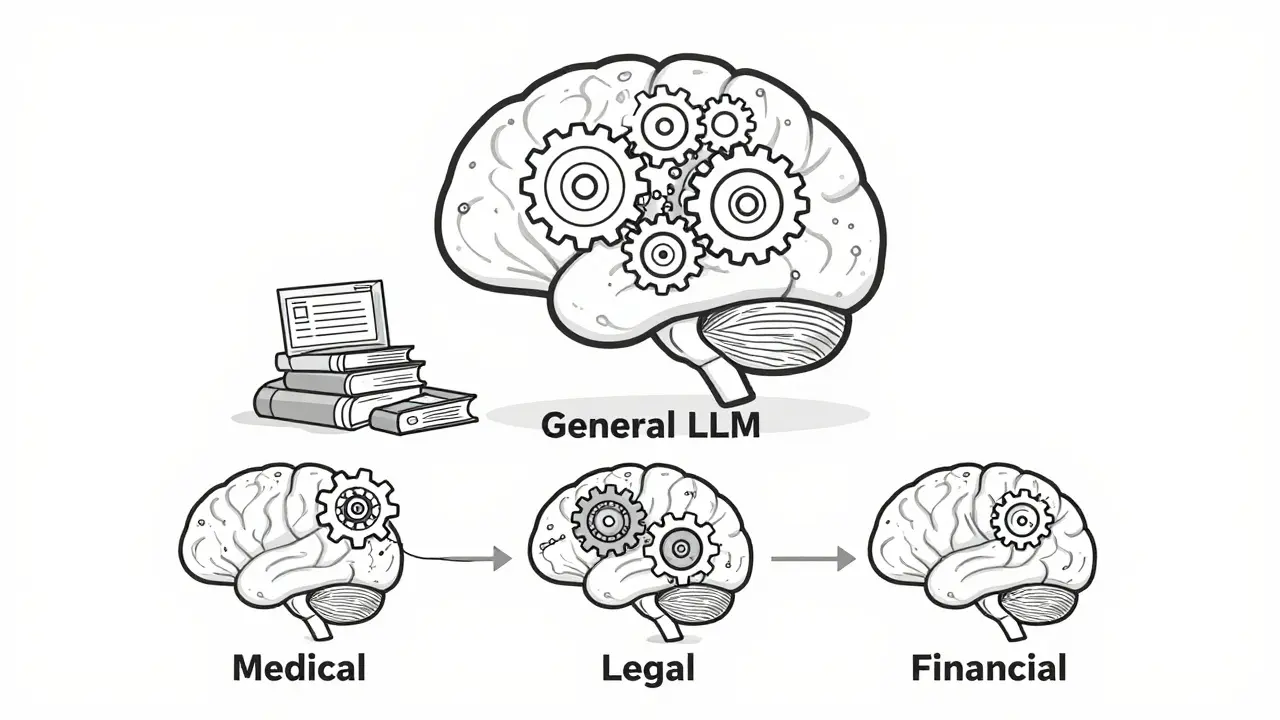
Domain adaptation in NLP lets you fine-tune large language models to understand specialized fields like medicine, law, or finance. Learn how it works, what methods deliver the best results, and why it's essential for real-world AI applications.

Vibe coding lets developers build full-stack apps using AI prompts instead of writing every line of code. Learn what to expect, how it works, where it shines, and where it fails - with real data from 2026.

Template repositories with pre-approved dependencies for vibe coding cut development time by up to 67% and reduce AI errors. Learn the top 4 templates, real risks, and who should use them in 2026.

Domain experts are now turning spreadsheets into full web and mobile apps using vibe coding-a method that uses AI to generate code from plain language prompts. No coding skills required.

Generative AI is reshaping leadership - not by replacing humans, but by freeing them to focus on what matters most: people, strategy, and trust. Learn how top leaders are using it to drive real change.
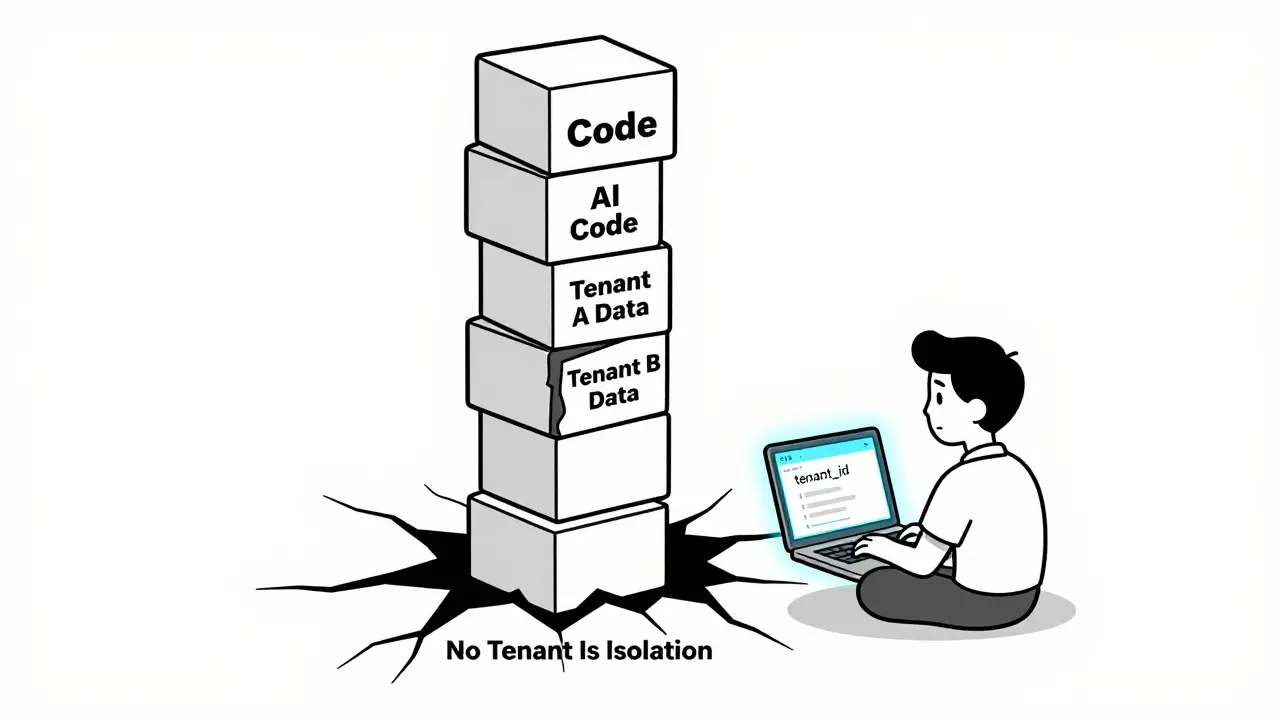
Multi-tenancy in vibe-coded SaaS requires careful isolation, authentication, and cost controls from day one. AI can speed up development-but only if you know how to prompt it right. Learn how to avoid costly mistakes and build secure, scalable SaaS apps.

Multimodal AI can generate images and audio from text-but it also risks producing harmful content. Learn how content filters for images and audio are evolving to block hidden threats, what providers like Google and Amazon are doing, and why current systems still fall short.

Large language models are transforming education by creating personalized learning paths that adapt to each student’s needs. From reducing teacher workload to helping students with disabilities, AI tutors are making learning more accessible-when used wisely.
Design tokens are the backbone of modern UI systems, enabling consistent theming across platforms. With AI automation, teams now generate and manage tokens faster than ever-cutting handoff time by 70% and ensuring accessibility compliance.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Localization and Translation Using Large Language Models: How Context-Aware Outputs Are Changing the Game
Nov, 19 2025

How Vibe Coding Delivers 126% Weekly Throughput Gains in Real-World Development
Jan, 27 2026
How to Structure Generative AI Outputs into JSON and Tables
Jun, 8 2026
Developer Sentiment Surveys on Vibe Coding: What to Ask and Why
Mar, 25 2026
Pretraining Objectives in Generative AI: Masked Modeling, Next-Token Prediction, and Denoising
Mar, 8 2026