
PCables AI Interconnects - Page 2

Implementing human-in-the-loop systems ensures safe generative AI deployment. Learn how to set approval workflows, manage exceptions, and balance automation with quality control using proven strategies.
Explore the conflicting data on vibe coding adoption in 2026. Learn what questions to ask in developer sentiment surveys to uncover real productivity gains, security risks, and trust levels.

Human oversight in generative AI isn't about slowing things down-it's about preventing costly mistakes. Learn how structured review workflows and risk-based escalation policies keep AI accurate, ethical, and accountable.

Discover which project types benefit most from AI-generated code. From CRUD apps to API integrations, learn where vibe coding saves time - and where it falls short.

Generative AI ethics require more than rules - they demand transparency, stakeholder involvement, and real accountability. Learn how universities, researchers, and institutions are building ethical frameworks that actually work in 2026.
Tiered governance for vibe-coded apps matches control intensity to risk, letting teams build fast without sacrificing safety. It replaces rigid policies with smart, automated checks that scale with impact.
Vibe coding tools today generate code fast but fail at system design, governance, and testing. The next wave must fix these gaps-or stay stuck as glorified snippet generators.

Large language models exhibit hidden biases from training data, human feedback, and internal architecture. New research reveals pro-AI bias, AI-AI bias, and methods to detect and fix them before they cause real harm.
Generative AI now personalizes customer journeys in real time, using over 500 data points to deliver tailored content that boosts satisfaction and revenue. Learn how it works, what it delivers, and how to avoid common pitfalls.

Maintainability SLOs turn vague engineering pain into measurable targets. Learn the key indicators-MTTR, deployment frequency, change failure rate-and how to set alerts that actually help teams ship better software faster.
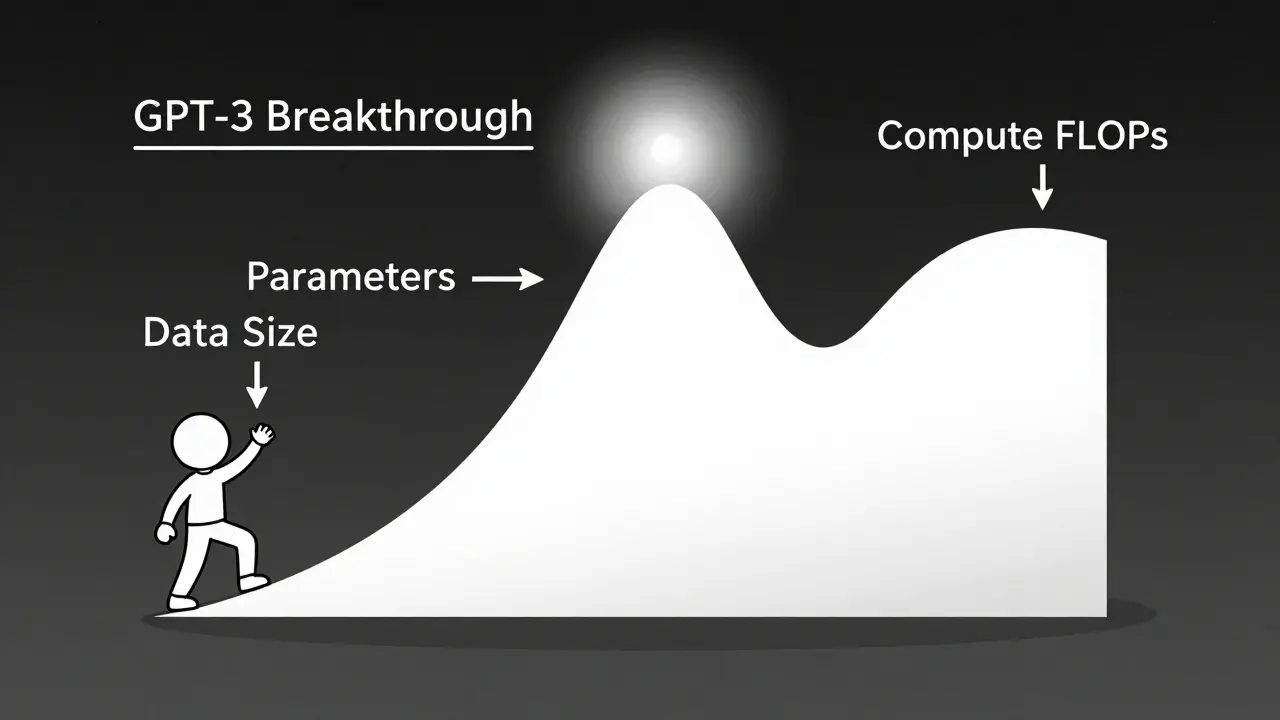
Scaling laws let you predict exactly how much performance improves when you increase model size, data, or compute. Learn how math, not just bigger models, drives AI breakthroughs-and why efficiency now beats raw scale.

Large Language Models are transforming contact centers by understanding customer sentiment and intent with unprecedented accuracy. From auto-generating summaries to predicting churn, LLMs turn raw calls into actionable insights that improve both customer experience and agent efficiency.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Customer Journey Personalization Using Generative AI: Real-Time Segmentation and Content
Mar, 17 2026
Developer Sentiment Surveys on Vibe Coding: What to Ask and Why
Mar, 25 2026
Preventing Catastrophic Forgetting During LLM Fine-Tuning: Techniques That Work
Apr, 1 2026

Allocating LLM Costs Across Teams: Chargeback Models That Actually Work
Jul, 26 2025

Localization and Translation Using Large Language Models: How Context-Aware Outputs Are Changing the Game
Nov, 19 2025