
Author: Phillip Ramos - Page 3
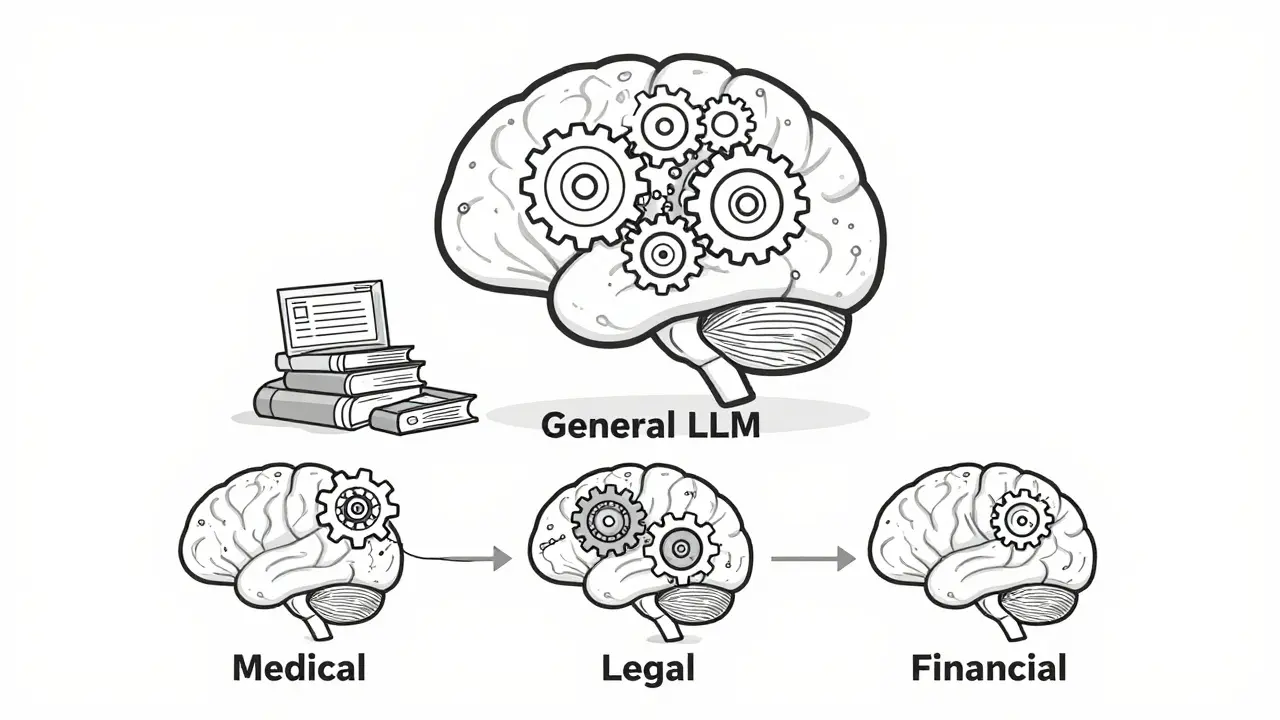
Domain adaptation in NLP lets you fine-tune large language models to understand specialized fields like medicine, law, or finance. Learn how it works, what methods deliver the best results, and why it's essential for real-world AI applications.

Vibe coding lets developers build full-stack apps using AI prompts instead of writing every line of code. Learn what to expect, how it works, where it shines, and where it fails - with real data from 2026.

Template repositories with pre-approved dependencies for vibe coding cut development time by up to 67% and reduce AI errors. Learn the top 4 templates, real risks, and who should use them in 2026.

Domain experts are now turning spreadsheets into full web and mobile apps using vibe coding-a method that uses AI to generate code from plain language prompts. No coding skills required.

Generative AI is reshaping leadership - not by replacing humans, but by freeing them to focus on what matters most: people, strategy, and trust. Learn how top leaders are using it to drive real change.
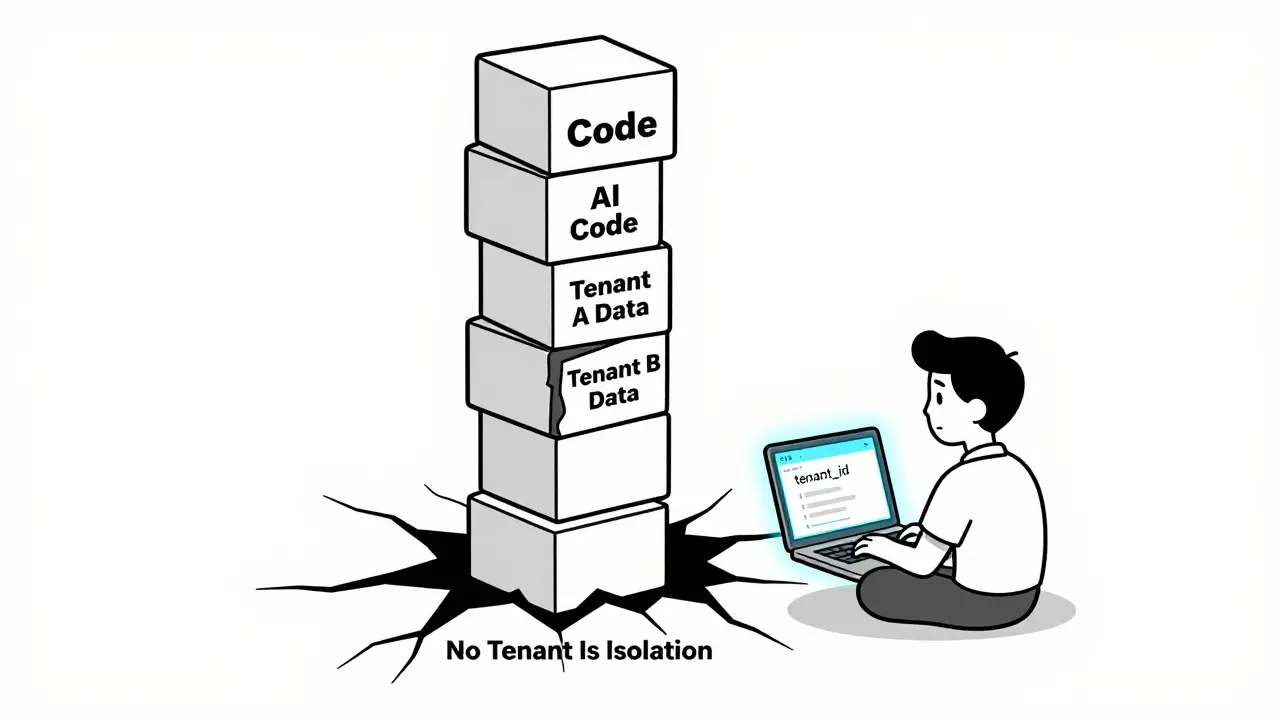
Multi-tenancy in vibe-coded SaaS requires careful isolation, authentication, and cost controls from day one. AI can speed up development-but only if you know how to prompt it right. Learn how to avoid costly mistakes and build secure, scalable SaaS apps.

Multimodal AI can generate images and audio from text-but it also risks producing harmful content. Learn how content filters for images and audio are evolving to block hidden threats, what providers like Google and Amazon are doing, and why current systems still fall short.

Large language models are transforming education by creating personalized learning paths that adapt to each student’s needs. From reducing teacher workload to helping students with disabilities, AI tutors are making learning more accessible-when used wisely.
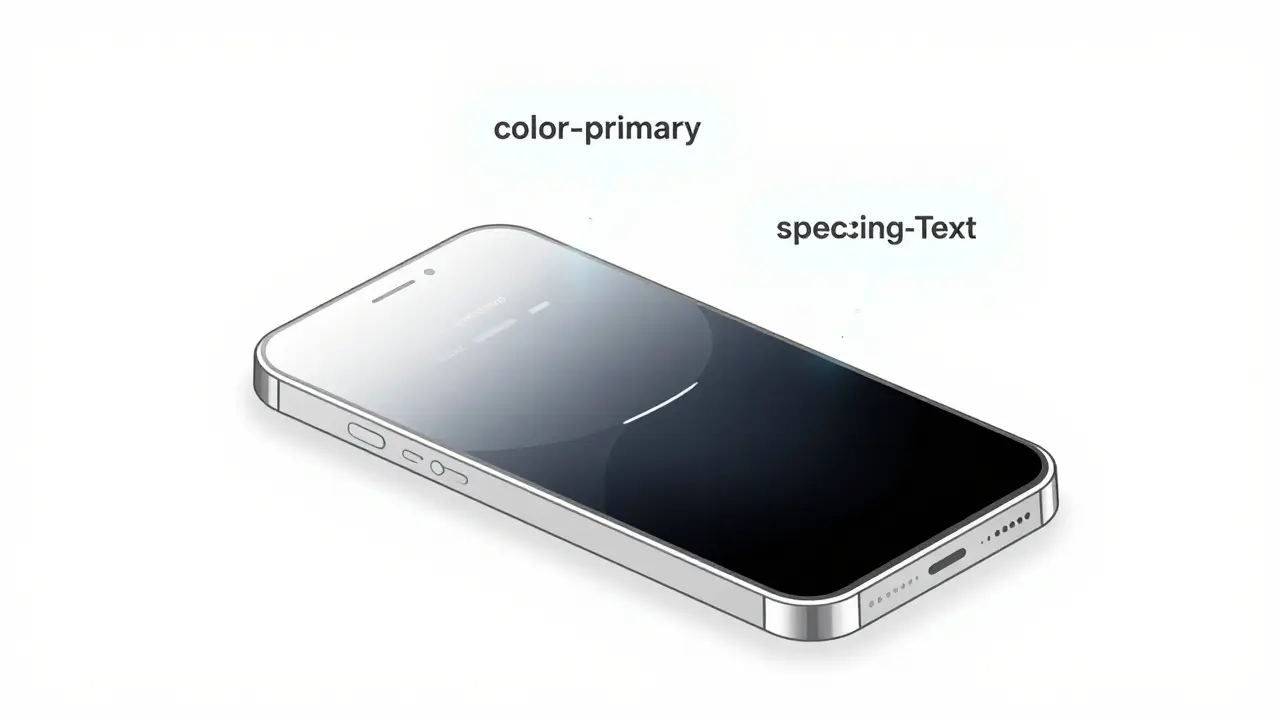
Design tokens are the backbone of modern UI systems, enabling consistent theming across platforms. With AI automation, teams now generate and manage tokens faster than ever-cutting handoff time by 70% and ensuring accessibility compliance.
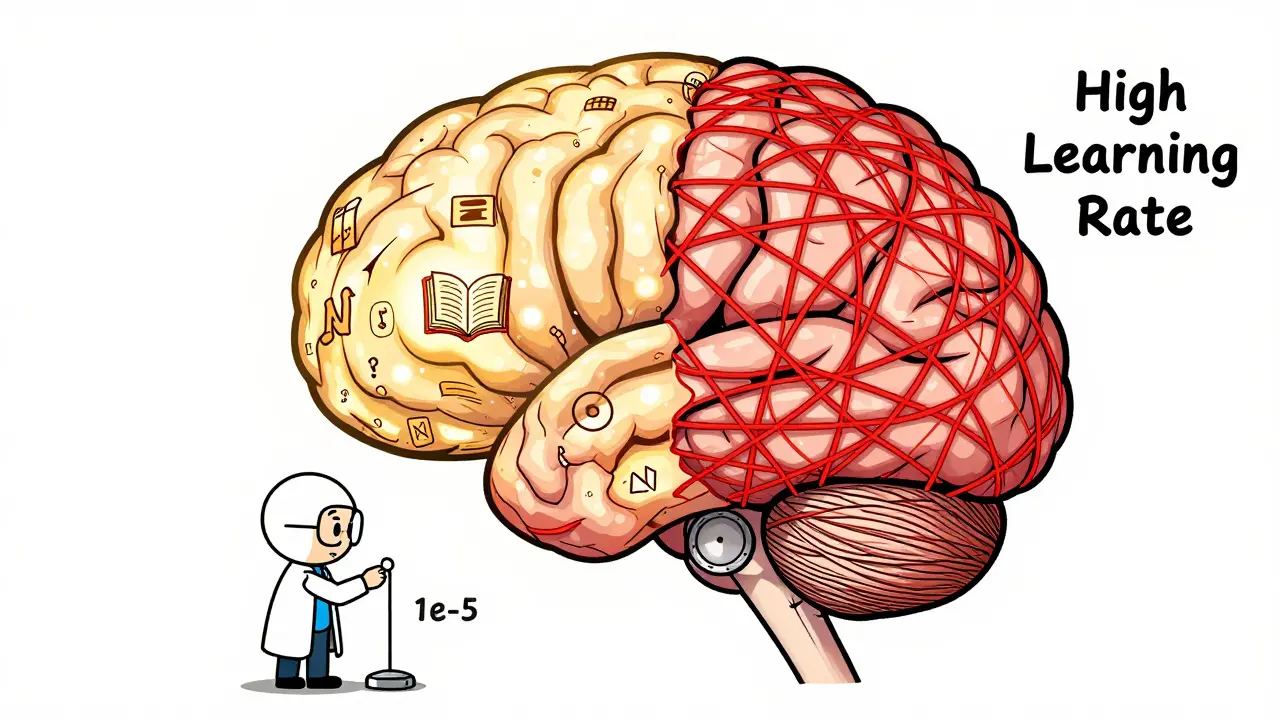
Learn how to fine-tune large language models without losing their original knowledge. Discover the best hyperparameters, methods like LoRA and FAPM, and real-world trade-offs that keep models accurate and reliable.
Few-shot fine-tuning lets you adapt large language models with as few as 50 examples, making AI usable in data-scarce fields like healthcare and law. Learn how LoRA and QLoRA make this possible-even on a single GPU.

Non-developers are building apps faster than ever using AI tools-but most don’t know how to secure them. Learn the three rules to avoid breaches, reduce risk, and ship safe vibe-coded apps without writing a line of code.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Prompt Sensitivity in Large Language Models: Why Small Word Changes Change Everything
Oct, 12 2025
Few-Shot Fine-Tuning of Large Language Models: When Data Is Scarce
Feb, 9 2026

How Finance Teams Use Generative AI for Smarter Forecasting and Variance Analysis
Dec, 18 2025

Safety in Multimodal Generative AI: How Content Filters Block Harmful Images and Audio
Feb, 15 2026

Generative AI for Software Development: How AI Coding Assistants Boost Productivity in 2025
Dec, 19 2025