
Category: Artificial Intelligence - Page 2

AI-generated UIs can speed up design, but without a design system, they create inconsistency. Learn how design tokens, governance, and human oversight keep components uniform across AI tools in 2026.

LLM prices have dropped 98% since 2023, but not all AI is cheap. Discover how competition and model specialization are splitting the market into commodity and premium tiers - and how to save money in 2026.

Domain-specialized generative AI outperforms general models in healthcare, finance, and legal fields by achieving up to 89% accuracy in specialized tasks. Learn why vertical expertise beats broad generalization in enterprise AI.
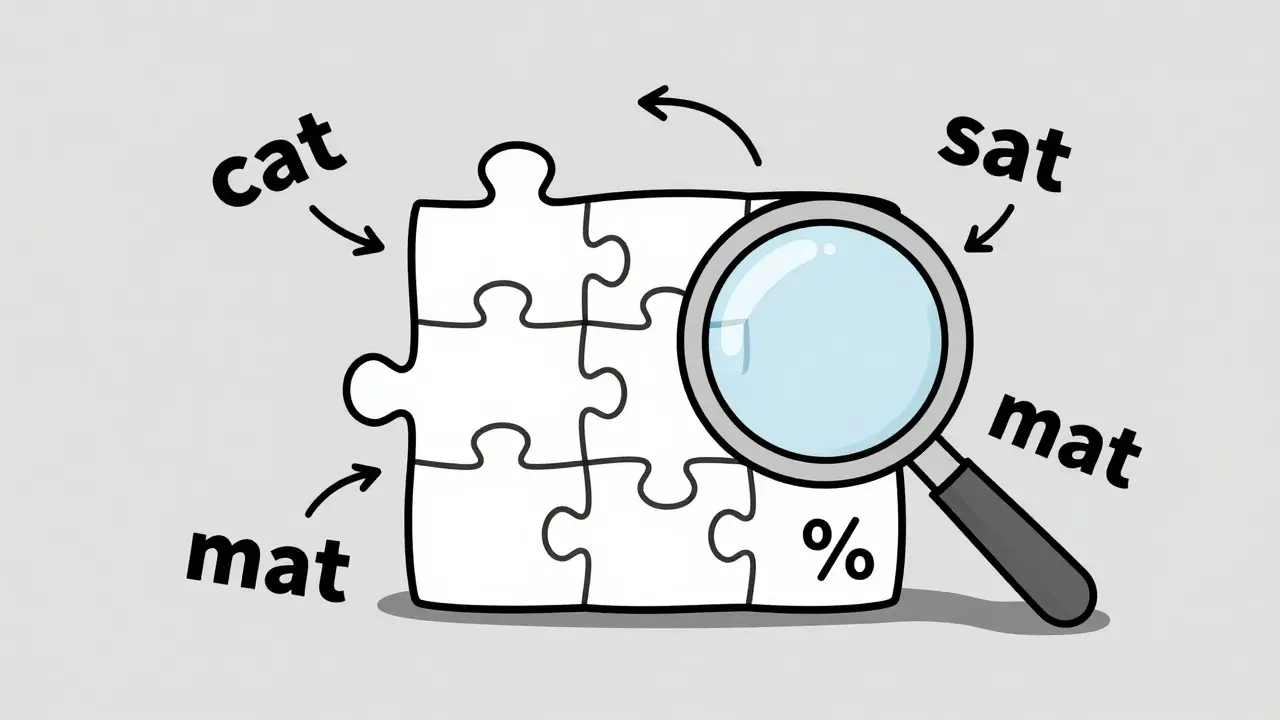
Masked modeling, next-token prediction, and denoising are the three core pretraining methods behind today's generative AI. Each powers different applications-from chatbots to image generators-and understanding their strengths helps you choose the right model for your needs.
Generative AI must comply with WCAG accessibility standards just like human-created content. Learn how to apply assistive technology requirements, avoid legal risks, and build truly inclusive AI systems.
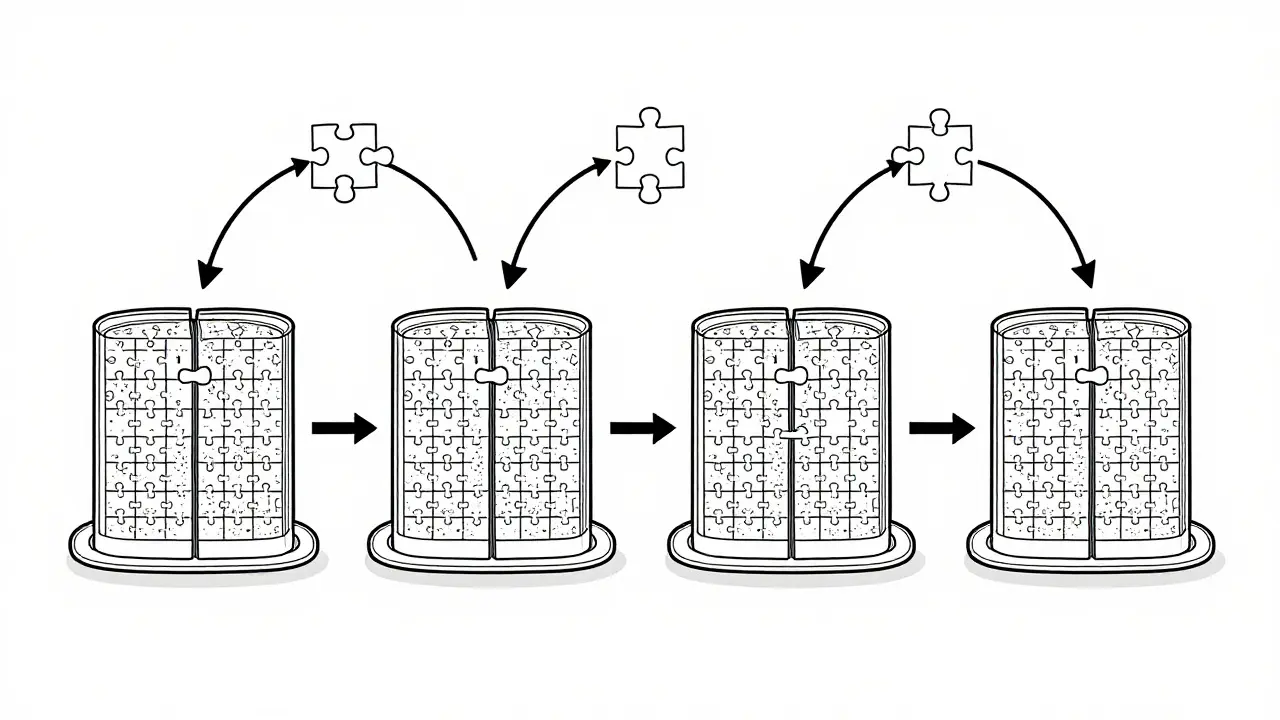
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.

Combining pruning and quantization cuts LLM inference time by up to 6x while preserving accuracy. Learn how HWPQ's unified approach with FP8 and 2:4 sparsity delivers real-world speedups without hardware changes.

Sandboxing external actions in LLM agents prevents dangerous tool access by isolating processes. Firecracker, gVisor, and Nix offer different trade-offs between security and performance. Learn which method fits your use case.

Structured prompts using role, rules, and context are the key to reliable enterprise LLM use. Learn how role-based prompting, chain-of-thought reasoning, and iterative testing improve accuracy, reduce hallucinations, and align outputs with business needs.

Choosing the right embedding model for your enterprise RAG pipeline isn't about benchmarks - it's about speed, security, and domain-specific accuracy. Learn what actually works in production and how to avoid costly mistakes.
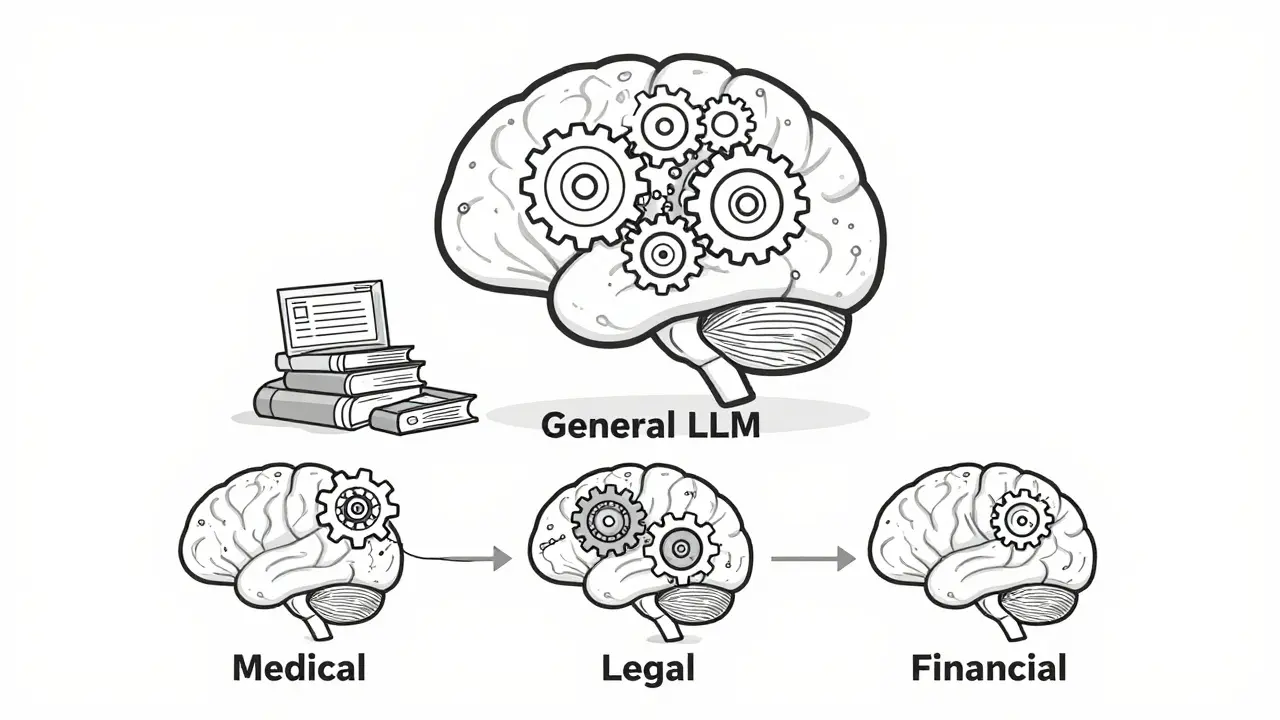
Domain adaptation in NLP lets you fine-tune large language models to understand specialized fields like medicine, law, or finance. Learn how it works, what methods deliver the best results, and why it's essential for real-world AI applications.

Template repositories with pre-approved dependencies for vibe coding cut development time by up to 67% and reduce AI errors. Learn the top 4 templates, real risks, and who should use them in 2026.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Predicting Performance Gains from Scaling Large Language Models
Mar, 15 2026

Fine-Tuned Models for Niche Stacks: When Specialization Beats General LLMs
Jul, 5 2025

Citation and Attribution in RAG Outputs: How to Build Trustworthy LLM Responses
Jul, 10 2025
Vibe Coding Policies: What to Allow, Limit, and Prohibit in 2025
Sep, 21 2025

Procuring AI Coding as a Service: Contracts and SLAs for Government Agencies
Aug, 28 2025