
PCables AI Interconnects - Page 10

Large language models exhibit hidden biases from training data, human feedback, and internal architecture. New research reveals pro-AI bias, AI-AI bias, and methods to detect and fix them before they cause real harm.
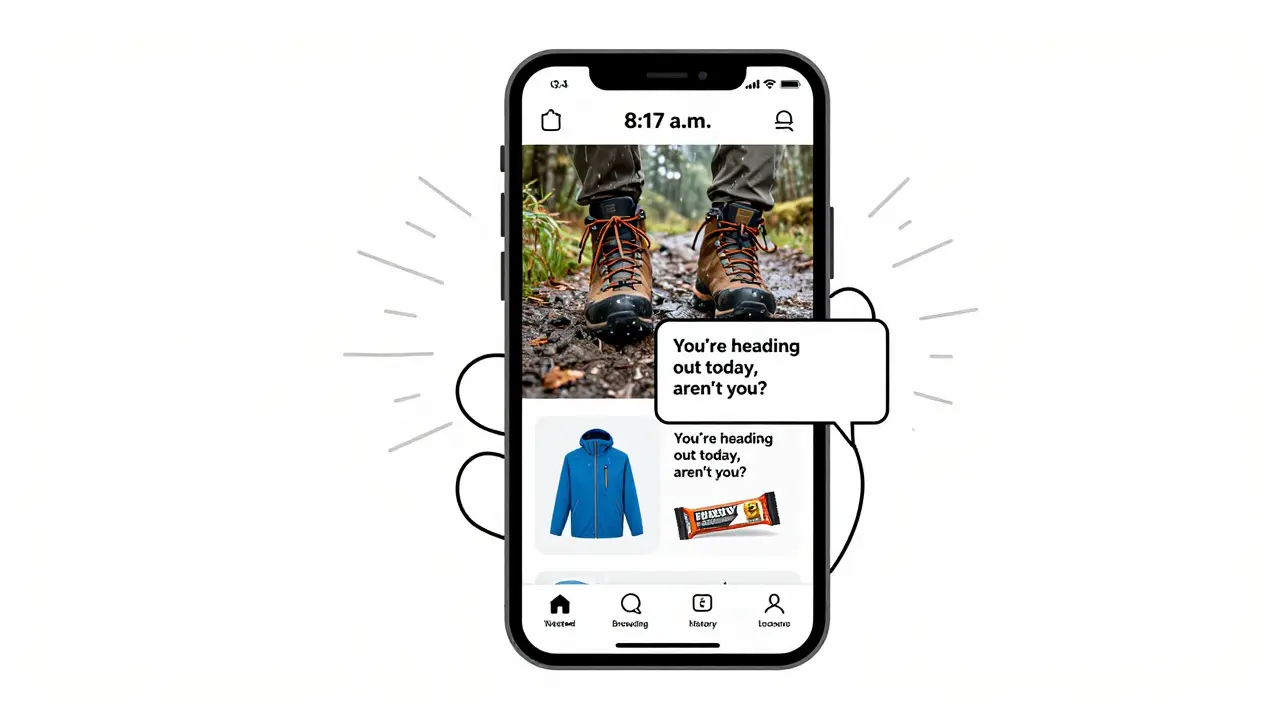
Generative AI now personalizes customer journeys in real time, using over 500 data points to deliver tailored content that boosts satisfaction and revenue. Learn how it works, what it delivers, and how to avoid common pitfalls.

Maintainability SLOs turn vague engineering pain into measurable targets. Learn the key indicators-MTTR, deployment frequency, change failure rate-and how to set alerts that actually help teams ship better software faster.
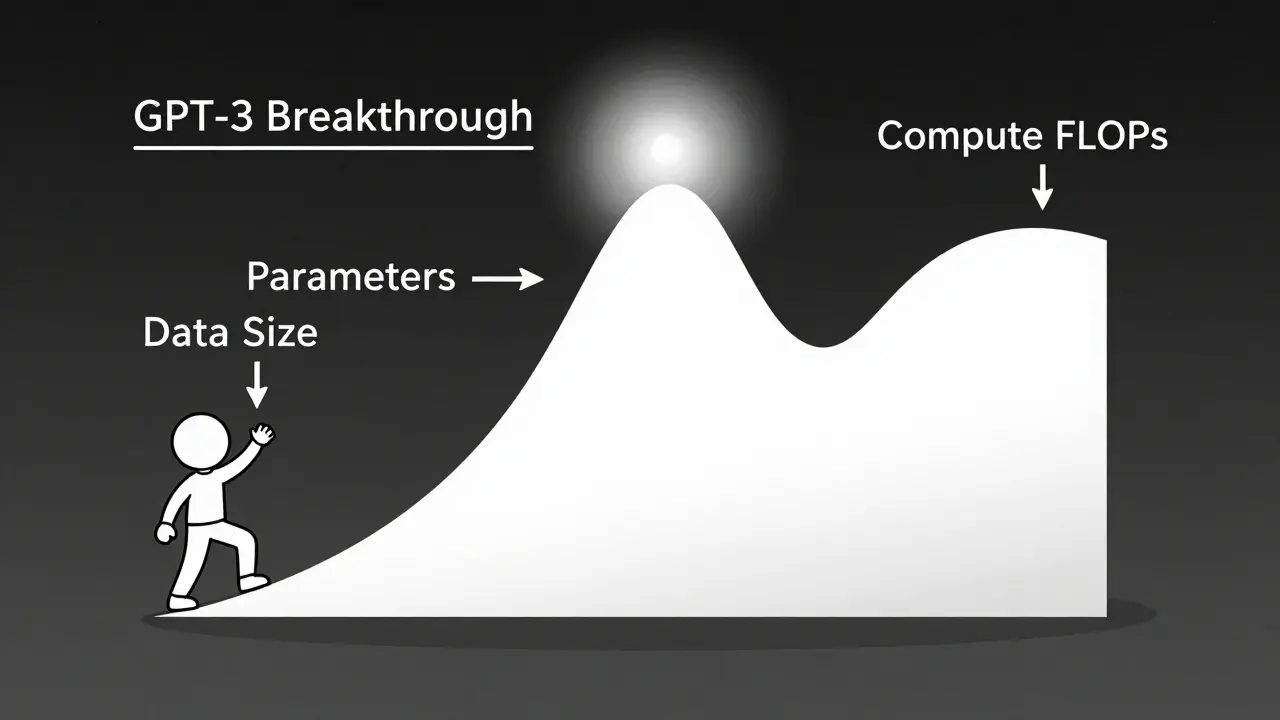
Scaling laws let you predict exactly how much performance improves when you increase model size, data, or compute. Learn how math, not just bigger models, drives AI breakthroughs-and why efficiency now beats raw scale.

Large Language Models are transforming contact centers by understanding customer sentiment and intent with unprecedented accuracy. From auto-generating summaries to predicting churn, LLMs turn raw calls into actionable insights that improve both customer experience and agent efficiency.

Stop sequences let you control how long AI-generated text gets, prevent hallucinations, cut costs, and ensure clean outputs. They're not optional - they're essential for any real-world LLM application.
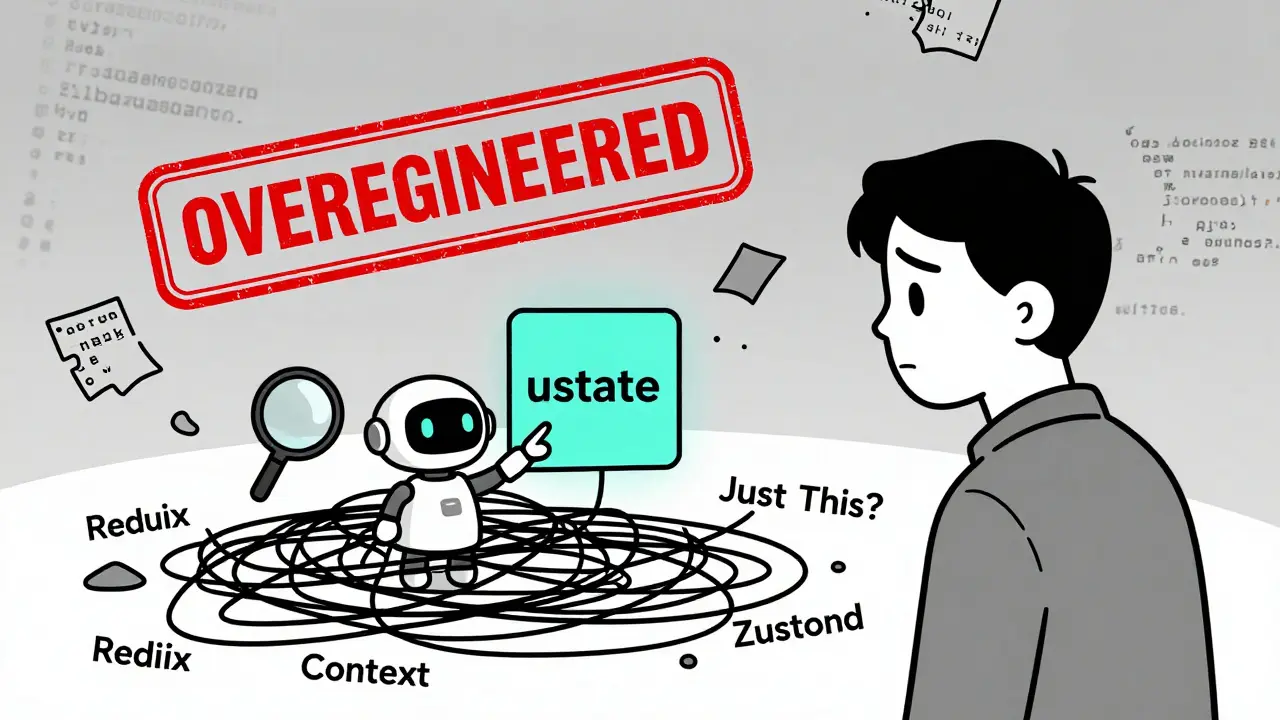
AI-generated frontends often misapply state management tools like Redux and Context API, leading to bloated, slow code. Learn the top pitfalls and how to fix them with Zustand, React Query, and AI-friendly architecture patterns.

AI-generated UIs can speed up design, but without a design system, they create inconsistency. Learn how design tokens, governance, and human oversight keep components uniform across AI tools in 2026.

LLM prices have dropped 98% since 2023, but not all AI is cheap. Discover how competition and model specialization are splitting the market into commodity and premium tiers - and how to save money in 2026.

Domain-specialized generative AI outperforms general models in healthcare, finance, and legal fields by achieving up to 89% accuracy in specialized tasks. Learn why vertical expertise beats broad generalization in enterprise AI.
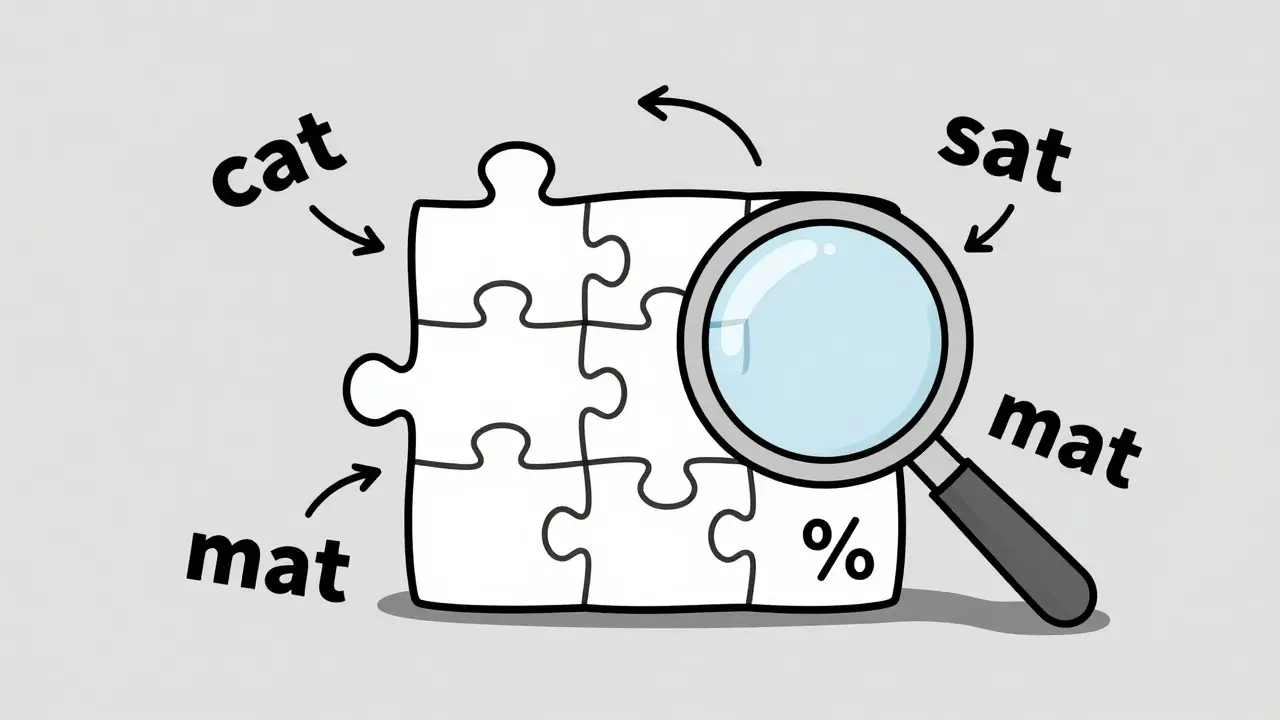
Masked modeling, next-token prediction, and denoising are the three core pretraining methods behind today's generative AI. Each powers different applications-from chatbots to image generators-and understanding their strengths helps you choose the right model for your needs.
Generative AI must comply with WCAG accessibility standards just like human-created content. Learn how to apply assistive technology requirements, avoid legal risks, and build truly inclusive AI systems.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

How to Choose the Right Embedding Model for Your Enterprise RAG Pipeline
Feb, 26 2026
E-Commerce Product Discovery with LLMs: How Semantic Matching Boosts Sales
Jan, 14 2026

The Future of Generative AI: Agentic Systems, Lower Costs, and Better Grounding
Jul, 23 2025
How to Structure Generative AI Outputs into JSON and Tables
Jun, 8 2026
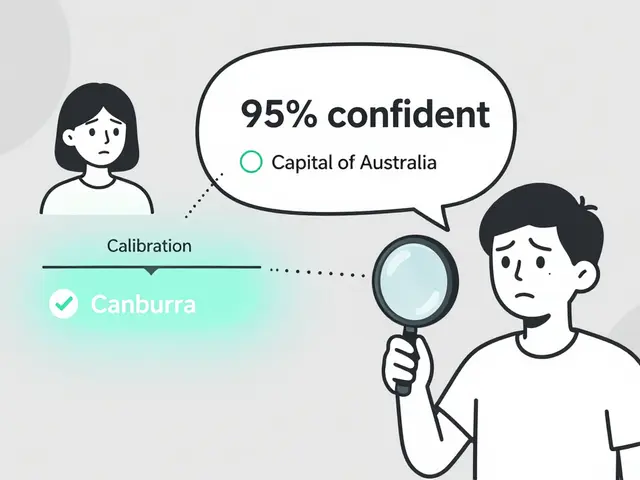
Token Probability Calibration in Large Language Models: How to Fix Overconfidence in AI Responses
Jan, 16 2026